
How to Architect Your Data for Scalable AI in SaaS (2026 Guide)
- Anna Perelyhina

- Mar 1
- 4 min read
In 2026, the gap between a successful AI feature and a failed one isn't the model you choose (GPT-5, Claude 4, or Llama 4). The gap is your Data Supply Chain.

If your data is fragmented, delayed, or unstructured:
Your AI will hallucinate.
Your AI will generate irrelevant outputs.
Your AI will burn tokens without generating revenue.
Your AI will fail in enterprise environments.
If your data is messy, your AI will be hallucinatory at best and a liability at worst. To scale, you don't need to be an engineer, but you do need to treat Data Architecture as a Product Feature.
To build a defensible AI moat, your SaaS needs more than a model; it needs an Inference-Ready Data Supply Chain.
What Is an “Inference-Ready Data Supply Chain”?
An Inference-Ready Data Supply Chain is a structured, real-time, governed data architecture that allows Large Language Models (LLMs) to:
Access unified user context
Retrieve only relevant information
Learn from user feedback
Operate within secure, isolated environments
Drive measurable revenue outcomes
Without this foundation, AI becomes a demo. With it, AI becomes a scalable revenue engine. Here is how to architect your data for scale.
1. The Mindset Shift: From Storage to Context
In traditional SaaS, we saved data so a human could look at it later (Reports/Dashboards). In AI SaaS, we save data so a machine can reason with it.
Simple Concept: The "Active Context" window
Think of your database not as a filing cabinet, but as a Briefing Folder for a high-speed executive assistant. If the folder is missing the last two months of notes, the assistant will give bad advice.
The PRD Requirement: The "Unified User State"
The Problem: Your user’s data is siloed
Usage data in Snowflake
Billing data in Stripe
Support sentiment in Intercom
CRM activity in HubSpot
Feature flags in internal SQL
Your AI cannot reason across silos
The Fix: You need a Data Lakehouse—a single source of truth that feeds the AI a "360-degree snapshot" of the user in real-time. The AI must know what the user did 5 seconds ago, not 5 hours ago.
Ask Engineering: "
Do we have a unified database where the AI can pull a user’s full history across all modules in under 100ms?
Can our AI access usage, billing, CRM, and support history in one call?
Is data real-time or batch-updated?
2. Mapping the Data-Need User Journey
This is the most critical task for a PM. Most PMs map the User Journey. Expert AI PMs map the Data-to-Action Flow. You must identify exactly what "fuel" is needed for every "automated spark."
Expert Scenario: The "Automated Account Expansion" Agent
Imagine an AI agent that identifies a user who is outgrowing their plan and drafts a personalized upgrade pitch.
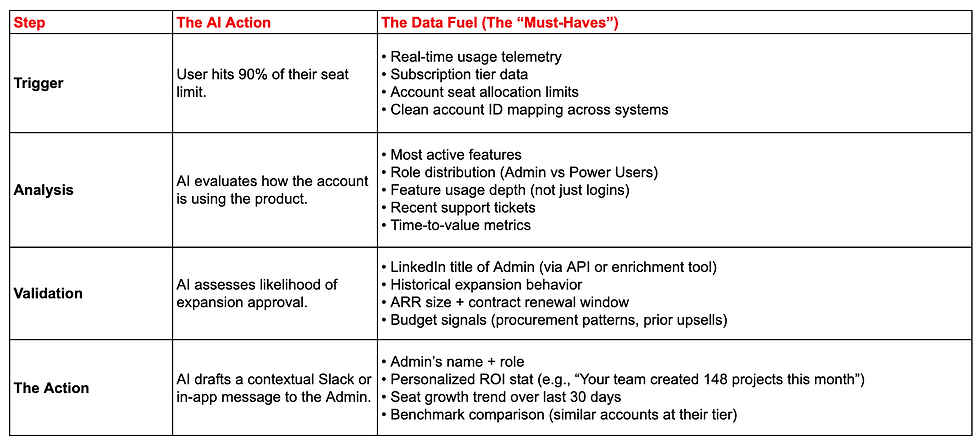
3. Building the "Data Flywheel" (Your Strategic Moat)
In 2026, the winner isn't who has the best model, but who has the best Feedback Loop. This is called RLHF (Reinforcement Learning from Human Feedback), but in simple terms: it’s "Learning from Edits."
The Requirement: "Implicit Signal" Tracking
Simple Concept: If your AI generates a report and the user manually changes a paragraph, that edit is gold. It tells you exactly what the AI got wrong.
The Infrastructure Requirement
You must log:
Original AI Output
User-Edited Final Version
The delta between them
The context window used
This creates a continuous improvement loop.
Ask Engineering: "Are we capturing 'Edit Deltas'? How are we feeding those corrections back into the model’s next prompt?"
4. Solving Token Burn (Protecting Your Margins)
Every piece of data you send to an AI costs money. Sending "Everything" is a recipe for a $0 margin business.
Terminology: Context Pruning (The "Editor" Layer)
Simple Concept: Instead of giving the AI a 50-page book of data, you use a "Ranking Layer" to give it the 5 most important sentences.
The PRD Requirement: Implement a Vector Database (like Pinecone or Weaviate) that performs "Semantic Retrieval." It finds the meaningfully relevant data, saving you thousands in API costs. In addition, your detailed user-journeys will help directing your AI.
Ask Engineering: "What is our 'Token Efficiency' strategy? How are we filtering out 'noise' before it hits the LLM?"
5. Security and Multi-Tenant Isolation (Enterprise Readiness)
If you want to sell AI features to enterprise customers, security is not optional.
Trust becomes your biggest product feature.
Terminology: Multi-tenant Context Isolation
Simple Concept: You need a physical digital wall that ensures Company A’s AI never "breathes the same air" as Company B’s data.
The PRD Requirement: Mandatory Metadata Filtering.
Ask Engineering: "How can we prove that User A's data is isolated from the Global Model's training set?"
The 90-Day Execution Roadmap for Founders and PMs
Days 1-30 (The Audit): Identify your "Data Silos." If your AI can't see your CRM, your AI is blind.
Days 31-60 (The Memory Layer): Deploy a Vector Store and start "Grounding" (giving the AI facts instead of letting it guess).
Days 61-90 (The Evaluation Loop): Create a "Benchmark Set." This is a list of 50 "Golden Questions" your AI must answer correctly before every update.
Is your infrastructure ready for the "Agentic" Shift?
Building AI that works requires a lot of effort. If you want to build AI that scales profitably you have to invest into data architecture.
At 8-Figure CPO we help SaaS founders bridge the gap between "Cool Demo" and "Enterprise-Grade Product."
Contact us if you want a free of charge audit of your current "Data-to-Action" flow and we will help you identify where your "Token Burn" is the highest?



Comments